Bayesian inverse problems have gained significant attention in recent years due to their strong mathematical foundations, which allow for thorough theoretical analysis. Moreover, the incorporation of measurement errors and noise is of utmost importance to obtain reliable results, for instance, in the context of computational imaging problems, such as computed tomography (CT) and magnetic resonance imaging (MRI).
Energy-based methods constitute a particular way to model probability distributions via Gibbs densities containing a suitable energy functional. These approaches can be used to model prior distributions in Bayesian inverse problems. The energy functional is parametrized, for instance, via fields of expert models and learned from image data using modern machine learning architectures. Thanks to its rich mathematical foundations, the Bayesian framework allows for rigorous theoretical guarantees regarding the obtained image reconstructions. A review paper on the topic of energy-based models for inverse imaging problems is available in [HHPZ2025].
A crucial challenge in learning the components of the prior from data lies in sampling from the prior distribution. Two methods, based on subgradient steps and the unadjusted Langevin algorithm, were developed in [HHP2024] and can also be applied to certain non-smooth potentials.
The success of neural network–based machine learning methods stems from their ability to accurately approximate a wide range of functions, enabling them to effectively address diverse real-world problems. This capability is rooted in universal approximation theorems, which position neural networks as versatile and powerful tools for tasks such as image recognition, natural language processing, and predictive modeling.
However, achieving this requires a deep understanding of expressiveness, which determines how well a neural network can capture intricate patterns. This understanding is also key to addressing challenges like overfitting and ensuring robust generalization to unseen data. The study of neural network architectures is also important, including the design of their structures and the choice of activation functions. Developing efficient architectures is a key goal because it ensures models that balance computational cost with high performance across these applications.
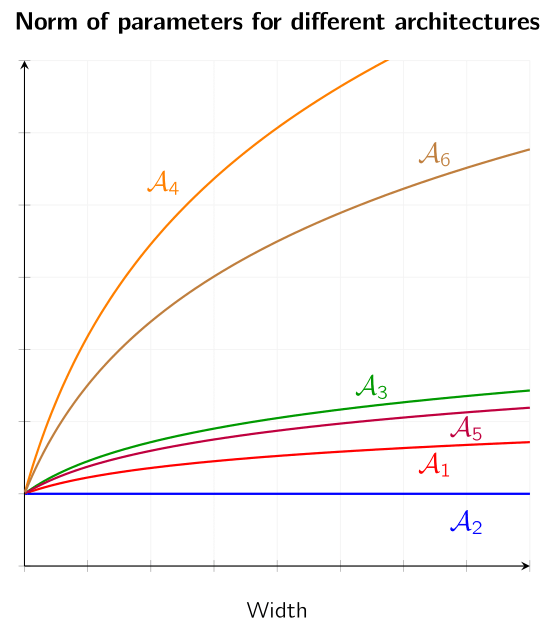
Our research group has investigated how the norm of parameters of approximating neural networks behaves asymptotically (see [HM2024]). This is a crucial factor for establishing consistency results in training and plays a significant role in our convergence results for structured model learning, as well as in conducting a full error analysis. In other work, we derived approximation results up to the first derivative with rates for neural networks that use rational functions as activation functions (see [HM2025]).
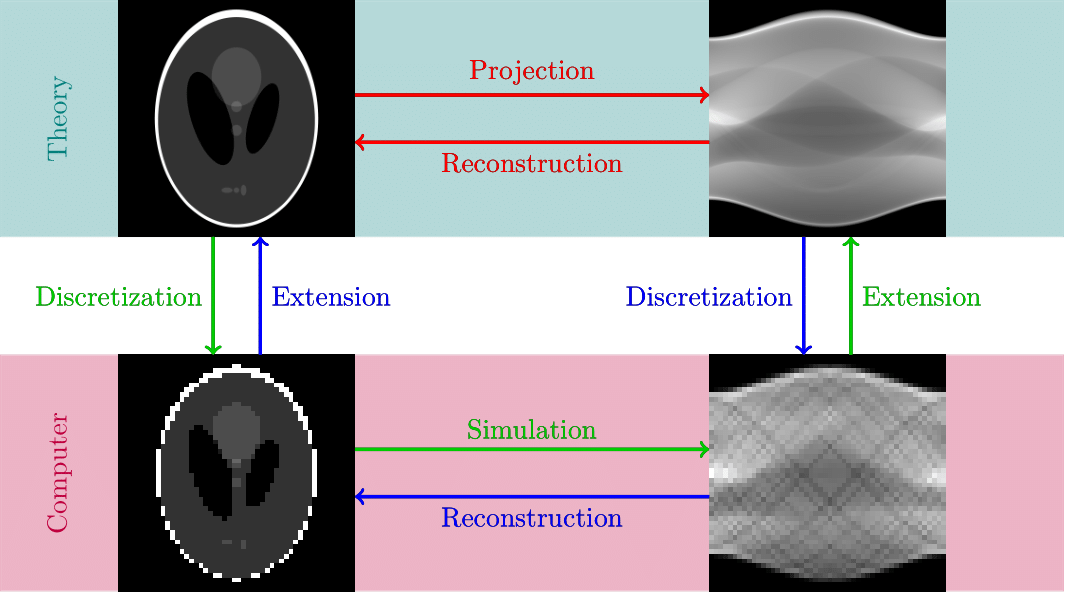
Hence, in practice, tomographic reconstruction is performed on computers using discretizations, i.e., reduced models of finite dimensions.
This naturally raises the question of whether the discrete problems are related to our continuous understanding of computed tomography. One cannot hope for discrete inverse problems to fully describe the infinite-dimensional setting; however, one would expect that when refining discretizations, e.g., by increasing resolutions, the discretizations are more and more representative of the infinite-dimensional situation.
The investigations move in multiple directions that benefit each other. Quite naturally the discrete forward operator should be as representative of the true operator as possible, a goal that leads to development of better discretization schemes. But that alone is not enough to guarantee that the solutions we obtained for the discrete problems, in fact, converge to solutions of the continuous inverse problem. Investigating for which methods and which senses this is the case is another key aspect of this project.Cardiac arrest remains a leading cause of death in the Western world, with survival rates around 10%. Timely treatment, including defibrillation and cardiopulmonary resuscitation, is critical for survival. To improve outcomes, analyzing real-world data is essential, yet difficult to obtain. Beyond documentation by emergency medical services, defibrillator recordings are a key data source but are typically limited by proprietary software that allows only predefined analyses.
Our group has worked on several aspects of analyzing defibrillator and physiological data from cardiac arrest cases in order to improve quality control and treatment guidelines in cardiac arrest. Buildin on a large dataset of deffibrillator recordings from cardiac arrest data, we have developed a standardized framework to process and annotate data independent of proprietary tools, a novel algorithm to detect chest compressions from accelerometer-based feedback sensors, and a machine-learning approach where data from accelerometer-based feedback sensors is combined with ECG recordings in order to predict the patient’s circulatory state.
Our work in this field is result of a collaboration with several colleagues from the University of Graz, the Medical University of Graz, the University Hospitals Schleswig-Holstein and Münster, and the German Society of Anaesthisiology & Intensive Care Medicine. As a result of this collaboration, we have implemented a automatic plotting and evaluation tool that is now being used in the German Resuscitation Registry to process data form cardiac arrest treatments throughout Germany and Austria, see here for an onlime demo.
To address this, a well-established strategy is to acquire only a reduced amount of data during an MR measurement and to compensate for the missing information using either hand-crafted or learned imaging models that incorporate prior knowledge about the structure of typical images.
Our research group is actively working in this field, particularly in the context of dynamic MRI. In our work, we have for example developed novel image reconstruction methods that reduce MRI data acquisition times by a factor of eight or more, without compromising the quality or diagnostic value of the reconstructed images.
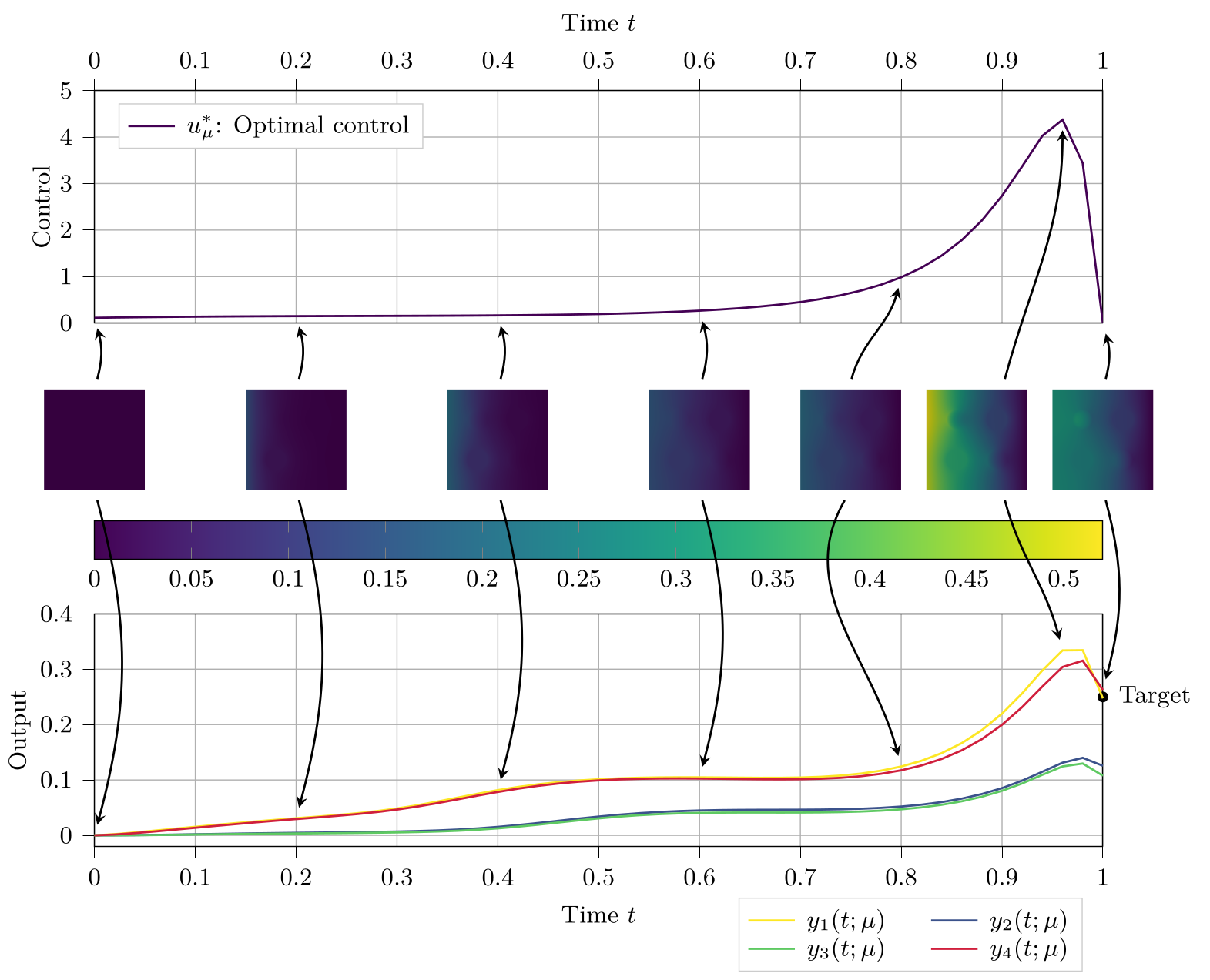
Optimal control problems play an important role in several areas of applied mathematics. The governing dynamical systems frequently involve parameters, and the resulting optimal control problem needs to be solved quickly for many different values of the parameters – for instance in a real-time or many-query context. Solving the exact optimal control problem is usually already costly for a single parameter. Hence, doing so for many values of the parameter is prohibitively expensive and infeasible in most applications.
We are interested in applying model order reduction combined with machine learning approaches. Such a combination has proven to achieve significant speedups while maintaining theoretical guarantees such as a posteriori error estimates. In particular, the certifications available for model order reduction methods, such as the reduced basis method, can be transferred to the machine learning prediction as well. This results in certified machine learning methods that are orders of magnitude faster than classical methods [KLM2025], [KR2025]. A purely data-driven method with certification using the high-fidelity model was developed in [KKLOO2022] to improve the results of enhanced oil recovery.
The aforementioned machine learning methods can be integrated in adaptive model hierarchies [HKOSW2023] consisting of a full order model, a reduced model and a machine learning surrogate. It is possible to apply different machine learning approaches [WHKOS2024] while maintaining the certification via the reduced basis approach. Such adaptive model hierarchies are automatically tailored to the parameters of interest and adjust dynamically depending on the performance of the individual components. In the context of parametrized optimal control problems, adaptive model hierarchies have for instance been applied in [K2024].
Most of the methods developed in this research topic are presented extensively in [K2025].
The methods developed in this research area contribute to Work Group 2 (ML for CT) of the COST Action InterCoML, in which we actively participate.
Positron Emission Tomography (PET) is a non-invasive imaging technique that uses radioactive tracers to visualize and measure metabolic activity in the body. By detecting gamma rays from tracer interactions, PET creates detailed 3D images of biological processes. Dynamic PET goes a step further by capturing a series of images over time, providing both spatial and temporal insights into how tracers move and interact, revealing metabolic rates and mechanisms. However, PET imaging faces significant challenges: Reconstructiong a PET image from corresponding measurements requires to solve an inverse problem with a highly ill-posed forward model. Further, PET raw data is usually corrupted by particularly strong noise, which is even more pronounced in dynamic brain PET.
Our research group works on improving PET imaging in several aspects: In some of our works, such as [SHRVKBBN2017, SH2022, SHKBKBN2017, KHKOBS2017] we deal with modelling- and algorithmic aspects of PET image reconstruction, developing efficient algorithms and MR-prior based approaches to improve the quality of the reconstructed images. In other works, such as [HM2024, HM2025], we address more fundamental questions regarding the unique identifiability of physiological parameters in PET tracer kinetic modeling.
Thus, preprocessing the data into a suitable form is a key step of tomographic reconstruction. To that end, detecting and correcting said corruptions prior to reconstruction is crucial. Doing so requires differentiation between plausible and implausible data.
One way to describe the plausibility of data is by checking whether they are in the range of tomographic projection operators describing the measurement process. The level of deviation from said range can indicate the level of corruption. However, how can we check whether data is in the range without doing reconstruction? Data in the range inherently possesses information overlaps between different projections that systematic corruptions will perturb.
Hence, the goal of this research is the characterization of tomographic projection operators' ranges and their related inherent information overlap. We develop general methods for characterizing the range of tomographic projection operators and describe how they can be employed in tomographic preprocessing.Most machine learning-based image segmentation models produce pixel-wise confidence scores that represent the model’s predicted probability for each class label at every pixel. While this information can be particularly valuable in high-stakes domains such as medical imaging, these scores are heuristic in nature and do not constitute rigorous quantitative uncertainty estimates. Conformal prediction (CP) provides a principled framework for transforming heuristic confidence scores into statistically valid uncertainty estimates.
Our research is dedicated to advancing both the theoretical foundations and practical applications of innovative, non-trivial conformal prediction methods aimed at improving the interpretability and reliability of image segmentation. In pre-print [VKH2025], we extend pixel-wise CP methods by developing CONSIGN (Conformal Segmentation Informed by Spatial Groupings via Decomposition), a method to leverage spatial correlation for improved results.
The following figure illustrates an example where ignoring the correlation between pixels results in inconsistent predictions and unrealistic pixel combinations. In contrast, our method effectively captures spatial and contextual dependencies, enabling the enforcement of structural constraints. As shown in the figure, our approach achieves a smooth and coherent transition between the segmentation of a sheep and a cow while offering valuable insights into prediction reliability.
The field of learning PDE-based models from data is growing rapidly. It is driven by the need to bridge physical principles with data-driven insights and enables successful advances in learning unknown parameters in partially specified PDEs, discovering entirely new PDE structures, and approximating solution operators with remarkable accuracy. Alongside practical applications, there is increasing attention to theoretical analysis addressing consistency, convergence, and generalization. These are essential for ensuring the reliability and robustness of learned models in scientific and engineering contexts.
Our research group focuses on the framework of "structured model learning." Structured model learning builds on approximate physical knowledge and addresses the limitations of overly coarse abstractions by incorporating fine-scale physics learned from data. This approach improves interpretability, accuracy, and generality, enabling the model to handle complex scenarios and external factors beyond the scope of simplified physical principles. Augmenting known physics with data-driven components enables the model to effectively describe phenomena, even in non-ideal or challenging contexts. However, it is crucial to learn only what is necessary to ensure that the augmentation remains efficient and grounded in physical understanding.
Our research group is actively engaged in structured model learning, focusing on both the theoretical foundations and the practical applications. We have investigated the unique identifiability of learned fine-scale physics and established a convergence result with practical relevance (see [HM2024]). Currently, a major focus of our work is learning multi-pool dynamics in magnetic resonance imaging (MRI).
Variational methods are a state-of-the-art approach for solving inverse problems in image processing and beyond. By employing suitable regularization functionals, variational methods enable provably stable and consistent reconstructions for a wide range of inverse imaging problems and effectively compensate for missing data through appropriate mathematical modeling.
Our research group has made several fundamental contributions to the field of variational methods for inverse problems. These include: